

One of my recent projects leveraging large language models (LLMs) for creative writing with a process called Soft prompt Training that was based on the paper “The Power of Scale for Parameter-Efficient Prompt Tuning” by Brian Lester, Rami Al-Rfou, and Noah Constant. Using GenAI for creative writing while combining soft prompt tuning, I aimed to enhance the creative writing process while preserving the unique voice of the writer.
What is soft prompt tuning?
The soft prompt technique allows you to fine-tune the model’s behavior by optimizing a small set of embeddings prepended to the input text. By using this technique you only use a small fraction of the model’s context window. The foundation model’s parameters are not changed as a result of external learning.
When you fine-tune a model, you alter it’s parameters and it may lose functionality or performance, otherwise known as overfitting. Especially with smaller datasets, like your own writing. Another advantage is using the same pretrained model instead of other fine-tuned models. Allowing for more efficient inferencing and storage.
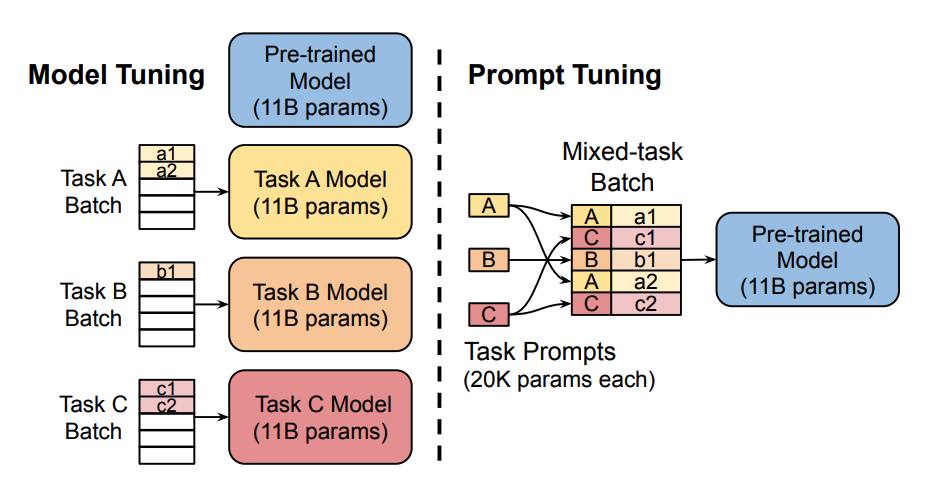
Soft prompts are learnable tensors concatenated with the input embeddings that can be optimized to a dataset; the downside is that they aren’t human readable because you aren’t matching these “virtual tokens” to the embeddings of a real word. With prompting, you can avoid fully training a separate model for each downstream task, and use the same frozen pretrained model instead. This is a lot easier because you can use the same model for several different tasks, and it is significantly more efficient to train and store a smaller set of prompt parameters than to train all the model’s parameters
Huggingface.co – Soft prompts (Image Source and above content.)
How can soft prompt tuning be applied to creative writing?
One of the main challenges in using Generative AI (GenAI) for creative writing is the risk of losing one’s unique writing voice. However, soft prompt tuning provides a potential solution to this problem. By training a soft prompt module on an individual’s own work, the generated text from an LLM, such as Meta’s Llama 3, can retain the writer’s distinctive voice.
The effectiveness of this approach depends on the quality of the dataset and data cleaning techniques employed. This depends on your dataset and data cleaning abilities, but as I stated earlier, soft prompt tuning is small dataset friendly. Something even more fascinating about this method is that you can combine modules!
Ready to get really creative? Combining modules!
Not only can you train these soft prompts on your own writing, think about the possibilities! Have you ever thought what your writing voice would sound like with the bias of Edgar Allen Poe or H. P. Lovecraft? This is absolutely possible with this method. You can combine modules during inference as along as your context window isn’t limited. The only limit you face is your own creativity!
Below is the link to my project with the code for creating soft prompts and using them with Mosaic ML’s MPT-7b-Storywriter which has a 65k token context window! An additional benefit of soft prompt tuning is the ability to train soft prompts on a smaller model variant and perform inference on a larger, more capable model, as long as they share the same model architecture. E.g. (Train the soft prompt on MPT-1b and inference the module on MPT-30b.)
The potential applications of soft prompt tuning in creative writing are immense and exciting. By harnessing the power of GenAI and soft prompt tuning, writers can enhance their craft, explore new creative avenues, and push the boundaries of their storytelling abilities without losing their creative side.
Project Link:
https://github.com/rs-1819/STIM
Have fun. I know I did! 😉
def load_softprompt_embedding(embedding_file, tokenizer):
softprompt_embedding = torch.load(embedding_file)
prompt_tokens = tokenizer(embedding_file.split(".")[0], return_tensors="pt")
input_ids = prompt_tokens["input_ids"]
return input_ids, softprompt_embedding

Leave a Reply